2020年乳品機械行業市場調查報告——聚焦食品機械領域
一、 行業概述
2020年,在全球經濟面臨復雜挑戰的背景下,中國乳制品行業作為重要的民生產業,保持了相對穩定的發展態勢。作為乳制品產業鏈的上游關鍵環節,乳品機械行業的發展與乳制品消費需求、生產工藝革新及政策導向緊密相關。本報告旨在通過對機械設備行業中電子機械設備與食品機械,特別是乳品機械細分領域的深入調查分析,揭示2020年的市場現狀、競爭格局、技術趨勢與未來前景。
二、 宏觀環境與政策影響
2020年,國家持續重視食品安全與產業升級。《中國制造2025》戰略的深入實施,以及“十四五”規劃的前期醞釀,為高端裝備制造業,包括智能化的食品加工機械,指明了發展方向。針對乳業,嚴格的食品安全法規(如《食品安全國家標準》)和產業振興政策,推動乳品生產企業持續進行設備更新與技術升級,以提升產品質量、生產效率和可追溯性,這直接拉動了對高性能、智能化、衛生標準更高的乳品機械的需求。
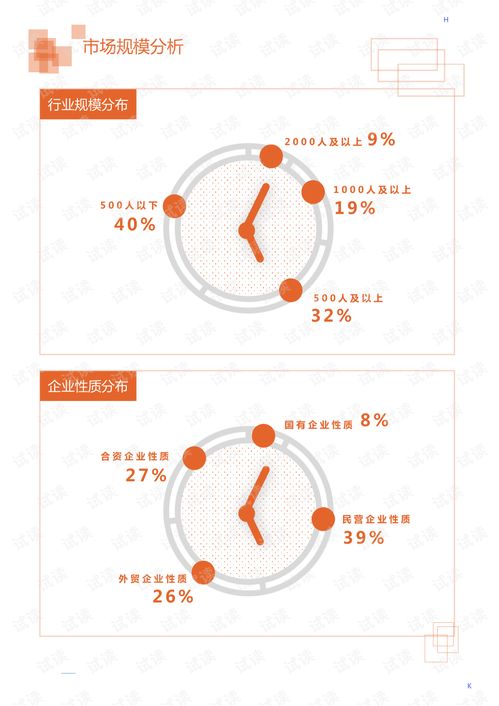
三、 市場規模與細分領域分析
- 總體規模:2020年,中國乳品機械市場規模在食品機械大類中占據重要份額。盡管年初受到疫情影響,部分項目延期,但隨著復工復產的推進和乳制品消費的剛性需求,市場在下半年呈現復蘇和增長態勢。市場驅動主要來自存量設備的升級換代和新產能的建設。
- 關鍵細分設備:
- 前處理設備:如收奶系統、儲奶罐、凈乳機、均質機等,市場需求穩定,技術向高效、節能、在線清洗(CIP)自動化方向發展。
- 滅菌與灌裝設備:超高溫瞬時滅菌(UHT)設備、無菌灌裝機是技術壁壘最高的領域之一,市場份額高度集中于少數國內外領先企業。消費者對長保質期、保留營養的液態奶需求,支撐了該領域的高端市場。
- 發酵與包裝設備:酸奶、奶酪等發酵乳制品品類的增長,帶動了發酵罐、菌種添加設備、酸奶灌裝線等需求的增長。包裝形式多樣化也推動了相應包裝機械的創新。
- 檢測與控制系統:隨著電子信息技術與機械的深度融合,在線質量檢測(如脂肪、蛋白質含量)、生產過程自動化控制系統(PLC、SCADA)的應用日益普及,成為提升行業整體水平的關鍵。
四、 競爭格局分析
- 國際品牌:如利樂(Tetra Pak)、斯必克(SPX)、基伊埃(GEA)等,在高端市場,尤其是無菌灌裝和大型生產線領域,憑借悠久的歷史、先進的技術和全球服務網絡,占據主導地位。
- 國內領先企業:國內一批優秀的乳品機械制造商,如新萊應材(部分業務)、普麗盛、中辰輕機等,通過持續的技術研發和市場積累,在中端市場具有強大競爭力,并逐步向高端領域滲透。其優勢在于性價比高、售后服務響應快、更能適應本土客戶的個性化需求。
- 市場競爭態勢:市場競爭日趨激烈,已從單一設備競爭轉向整體解決方案和全生命周期服務的競爭。價格戰在標準化中低端設備領域存在,但在高技術含量、高自動化程度的核心設備領域,技術、品牌和可靠性仍是關鍵競爭要素。
五、 技術發展趨勢
- 智能化與數字化:工業互聯網、物聯網(IoT)、大數據分析技術正與乳品機械深度融合,實現設備遠程監控、預測性維護、能源管理和生產數據可視化,助力打造“智慧工廠”。
- 柔性化生產:為適應市場小批量、多品種的需求,模塊化設計和柔性生產線配置成為重要方向,使同一生產線能夠快速切換生產不同產品。
- 衛生與安全標準提升:設備設計更注重無衛生死角、易清潔消毒,材料符合食品接觸安全法規(如FDA、EC1935/2004),自動化清洗滅菌系統成為標配。
- 節能環保:節能減排壓力下,高效熱交換技術、熱能回收系統、低耗水CIP系統等節能型設備更受青睞。
六、 用戶需求與采購行為
乳品生產企業(用戶)的采購決策更加理性與綜合化。主要考慮因素包括:
- 設備性能與可靠性:確保生產連續穩定和產品品質。
- 總擁有成本(TCO):不僅關注初次采購價格,更重視運行能耗、維護成本、備件價格和停機損失。
- 技術兼容性與升級能力:新設備需能與現有生產線有效銜接,并具備未來技術升級空間。
- 供應商服務能力:安裝調試、技術培訓、快速響應的售后維護及備件供應體系至關重要。
七、 挑戰與機遇
挑戰:
關鍵核心技術與高端部件(如某些泵閥、傳感器)仍依賴進口。
原材料價格波動對制造成本帶來壓力。
* 下游乳品行業集中度高,大客戶議價能力強。
機遇:
消費升級帶動高品質、功能性乳制品增長,催生對先進設備的需求。
國家政策鼓勵裝備自主化和智能制造,為國內優秀廠商提供發展窗口。
海外市場,尤其是一帶一路沿線國家,存在設備出口和產能合作潛力。
奶酪、植物基乳制品等新興細分市場的興起,帶來新的設備需求點。
八、 結論與展望
2020年是中國乳品機械行業在壓力中探索轉型與升級的一年。市場在波動中展現出韌性,技術創新的驅動作用愈發明顯。行業整合將加速,擁有核心技術創新能力、能夠提供智能化整體解決方案的制造商將獲得更大發展空間。可持續發展理念將更深地融入設備設計與制造中。對于市場參與者而言,緊跟下游消費趨勢,深耕細分領域,加強產學研合作以突破技術瓶頸,并積極布局數字化服務,是構建長期競爭優勢的關鍵。預計“十四五”期間,乳品機械行業將朝著更智能、更高效、更綠色的方向穩步發展。
如若轉載,請注明出處:http://www.yongyuebao.cn/product/61.html
更新時間:2026-04-16 12:20:51